Data collection is key. Healthcare now relies on increasingly large amounts of data for maximizing both artificial intelligence (AI) and revenue cycle management (RCM) systems. BHM Healthcare Solutions understands the value of data in getting healthcare organizations to next-gen analytics.
Today’s blog begins at the beginning, collecting data. BHM wrote this article, by our Senior Data Analytics Consultant, David Shaffer, as the first tool in your data collection toolbox. While there are many reasons to collect data, David was working on a project with a client to gather data for competitive analysis and enable them to stay ahead of their competition without hours of manual data searching, entry, cleaning, and review.
As your IT teams amass more and more data, look to BHM as your independent healthcare analytics consulting resource. For more information on our services, contact BHM using our services form HERE or call 888-831-1171. Ask our representative for more information about our business intelligence services.
Before getting to David’s blog, the links (below) present some background to today’s topic.
How To Extract Web Content
Web Data Extraction: Beginner to Advanced
Web Data Collection Wiki
Web Data Collection, sometimes called web scraping, is the process by which we obtain information from the HTML (HyperText Markup Language) of a web page. In this article, we’re going to talk about why we might want to do this and walk through the steps involved from a coding perspective.
Why use data collection from the web?
Did you know there are around two-hundred MILLION active websites on the internet today? That’s two-hundred million sources of data that we can collect from. Now you can argue that the quality of the data we might gather from a majority of these is questionable at best, but nonetheless, it is still data.
Companies you’ve probably heard of, like Kayak, deploy bots at scale to capture data from websites and perform price comparisons for you, to save you the time required to go to each company’s page and compare prices yourself. Ecommerce is another popular space where web scraping is used to analyze who is buying what, when, and for how much, to gain an advantage over their competitors.
In this article, we are going to scrape data from Amazon, with the goal of capturing the prices for office chairs sold by Amazon Basics. We won’t go over the steps involved to store, manipulate, and analyze that data after we scrape it. That will be for another article. However, we will use a bot to open Amazon’s web page using Selenium for Python and navigate to the page we want automatically without the click of a mouse. Then, we will scrape the page for the prices and cleanse the data.
Using a bot to open and navigate through a website
Very simply, Selenium automates browsers. It’s primarily used for testing. But in many cases, it serves as a useful tool for gaining efficiency with repetitive processes.
Step 1: Import webdriver package.
![]()
Step 2: Download Selenium webdriver.
- Make sure you choose the right driver for your specific browser and Operating System. I am using Chrome on Windows. So I’ve downloaded the Chrome driver for Win32 and placed it in my Documents folder. Then I’m going to refer to the location when defining my “browser” variable.
![]()
Step 3: Open browser with bot
- Use the function get and pass the web page address as the argument
![]()
Step 4: When you open a web page and it isn’t loaded instantly, that’s because it’s taking time for the HTML to load. This is a great time to use the function sleep to allow for the page to load. If we don’t do this, Python will move to the next line in the script and try to execute it and when acting on HTML, if the HTML hasn’t yet loaded, your program will throw an error.
Step 5: Enter the product you want to search for in the Search box. In this case, we are going to search for “office chair”.
- This is where Selenium can get tricky. To enter text into the Search box, we must first find a way to identify the element from the HTML. You can click F12 on your computer to open the browser page’s HTML.
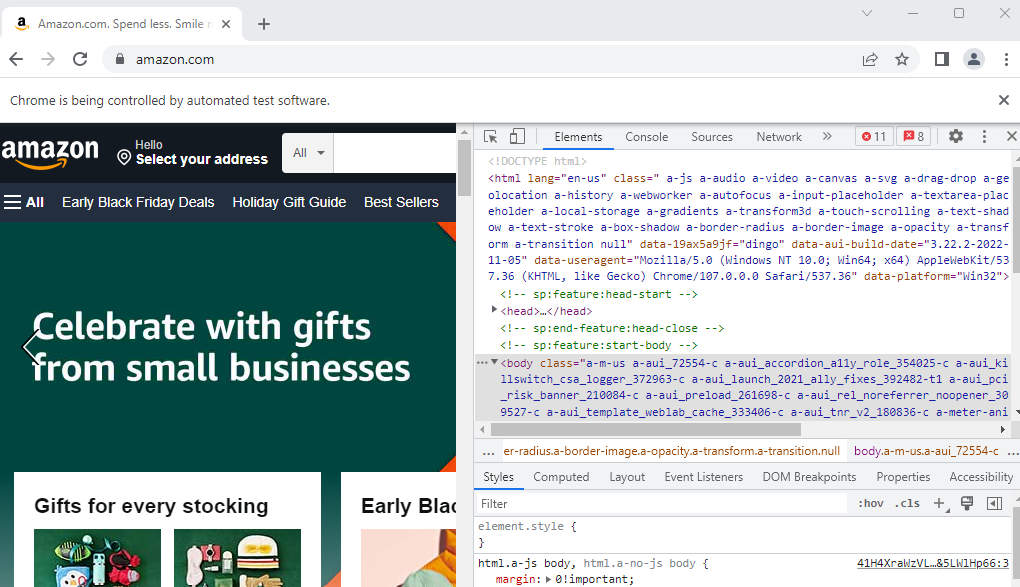
- Notice how there is a notification along the top of the page that says, “Chrome is being controlled by automated test software”. In many cases, this can be detrimental to our efforts as many websites, such as Zillow, block automation tools like Selenium. When you try and navigate through their page with a bot, it will take you to a page that requires you to pass a test to prove you are a human.
- Now that we’ve opened the HTML, the fastest way to get to the element we want to access is by clicking the arrow-inside-the-box icon along the top of the inspection pane.
- Then, click on the element on the website that you want to access. This will bring you to the element’s HTML.
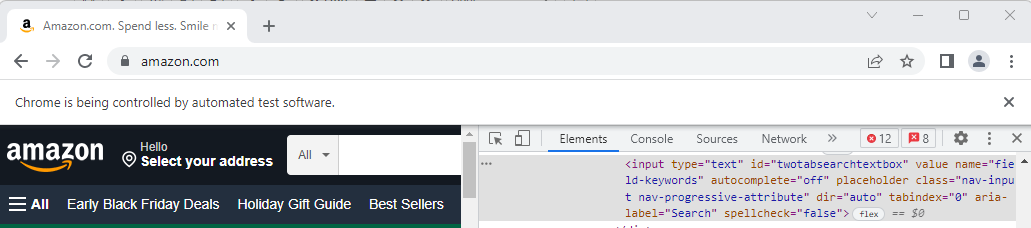
- Identifying an element by its id is always a good place to start if the id appears to be unique to that element. So I am going to find the element by the id and use the function send_keys to type into the Search box.

Step 6: Search!
- Identify the element, in this case, the magnifying glass, and click it.
![]()
Step 7: Allow the page a few seconds to load.
![]()
Step 8: Filter for products sold by Amazon Basics.
- In many cases, we are unable to identify an element by its id. In this instance, I am identifying it by its xpath. To learn about all the ways to identify an element, be sure to check out this page (https://selenium-python.readthedocs.io/locating-elements.html) and save it in your favorites. I reference it all the time while writing Selenium scripts.
![]()
Step 9: Allow the page a few seconds to load.
![]()
Step 10: Filter for products with a 4-star rating or higher.
![]()
Using Beautiful Soup package to extract data from the HTML
So far, we’ve used Selenium to access the HTML to navigate through web pages, but we can’t use Selenium to extract the text within the HTML. That’s where Beautiful Soup comes in!
Step 11: Define your Beautiful Soup variable
![]()
Step 12: Extract prices.
- This step can be the most difficult of all the steps we’ve covered up to this point. Using the function find_all, we can identify the values inside all the price elements. But we must first identify the tag used to house the prices. Here is how one of the prices on the page looks like in the HTML.

- After reviewing a few of the prices, I see that they are all tagged in a similar manner, so I write the following code to extract all of them. I must define the attrs argument to tell my code in more detail, which “span” tags to pull information from because the prices aren’t the only HTML lines that use a “span” tag.

- I defined a variable in this step because I need to manipulate the Output. Just to show what the Output looks like at this point though…
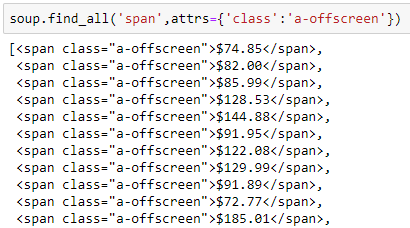
Step 13: Manipulate the output.
- Using a standard Python list comprehension, I want to end up with just a list of the prices.


- Using the len function and then the mean function from the statistics package, we can see the quantity and the average price of Amazon Basics office chairs with a 4-star rating or higher that are currently listed for sale on Amazon.

You can see how something like this, done with many bots on a regular basis, can obtain useful data for analyzing your competition’s prices…and all without you having to click a single button!
Data and Security go hand-in-hand within healthcare. Download HITRUST Origin Story for how security and healthcare came together.
| Editor’s Note: BHM Healthcare Solutions understands the value of data in getting healthcare organizations to next-gen analytics. For more information on our services, contact BHM using our services form HERE HERE or call 888-831-1171 and ask our representative for more information about our business intelligence services. |